我们的故事要回到 1974 年,彼时计算机主要形式还是大型机,创造计算机行业历史的 Apple I 要在两年后才正式面世,而我们熟知的万维网(World Wide Web)在整整十五年后才会被伯纳斯-李爵士在他的《关于信息化管理的建议》中提出。在那时我们现在使用的互联网还未出现,当时有的只是「阿帕网」——一个仅有4个节点构成的小型网络。而在 1973 的夏天到 1974 年的这段时间,来自康涅狄格州和出身自纽约的犹太人家庭的两位年轻人,他们在斯坦福的网络研究组里设计和开发出了一个叫做 TCP/IP 协议。正如上帝要把祂的教会建立在磐石之上在,TCP/IP 协议最后也成了我们网络世界的「磐石」。这两位年轻人:文顿·瑟夫和罗伯特·卡恩,也在三十年后的 2004 年,获得了计算机科学领域最贵重的那只碗——图灵碗。
当然我们的故事还要继续,在几乎同一时期的中国大陆,一位叫做张丽霞的年轻女性受到了文革的影响,正在田野中开着拖拉机。她在文革结束后来到了美国,并在美国获取了硕士和博士学位。后来她在 1986 年作为 21 人中唯一的女性和唯一还是学生身份的人的参加了第一次的互联网工程任务组会议。而这个「小组」最后成长为了一个负责互联网规范制定与研发的庞大组织。在几年后范·雅各布森, TCP/IP 协议最初的起草者中的其中一位,重新设计了 TCP/IP 的流控制算法,并和他人一起合作编写了一系列如今软件工程师们仍在使用的网络工具:traceroute、pathchar 以及 tcpdump。在 2006 年 8 月的 Google Tech Talk 上做了一个叫做《A New Way to look at Networking》的演讲,在这个演讲中,他提出了一个名叫「Named Data Networking」的全新的网络架构,并在此后的多年里和张丽霞教授一起领导着这个项目的研究。而这个项目正是我们今天的主角:命名数据网络,简称 NDN 网络。
为了理解什么是命名数据网络,以及命名数据网络为什么重要,我们得先理解现有的 TCP/IP 网络的模型是什么样子的,我们先从 TCP/IP 网络的定义着手。
TCP/IP 提供了点对点连结的机制,将资料应该如何封装、定址、传输、路由以及在目的地如何接收,都加以标准化。
这句话中的「点对点」的意思是,在 TCP/IP 模型中,设备获取内容的主要方式是从另一台计算机那里下载。当然这么说还是很复杂,我们来看一个详细的例子。
首先我们要明白,在 TCP/IP 模型中,在一个网络中每一个计算机都有一个独属于它的 IP 地址,而计算机则是用 IP 地址来表联系网络中另一台计算机。任意一台计算机上的资源都可以表示为下面的形式。
1 | file://119.23.141.248/index.html |
上面描述了一台 IP 地址为 119.23.141.248 的计算机上的一个叫做 index.html 的文件,这里的 file:// 只是一个前缀标识而已,不用过于在意。而其他的计算机要获取这个文件必须要向这台计算机发送请求,与这台计算机建立一个传输数据的通道,然后才能开始正式传输数据。
可以看到在 TCP/IP 模型中,IP 地址是寻找内容时的核心,而「通道」则是传输内容的核心。但是如果你仔细想想,我们想要的只是获取获取到这个 index.html 文件而已,其实并不想也并不需要关心这个文件具体存放在什么地方。而我们也不想关心通道,我们只是想要内容而已。
那么这个模型有什么问题呢?想象下面这个情况。
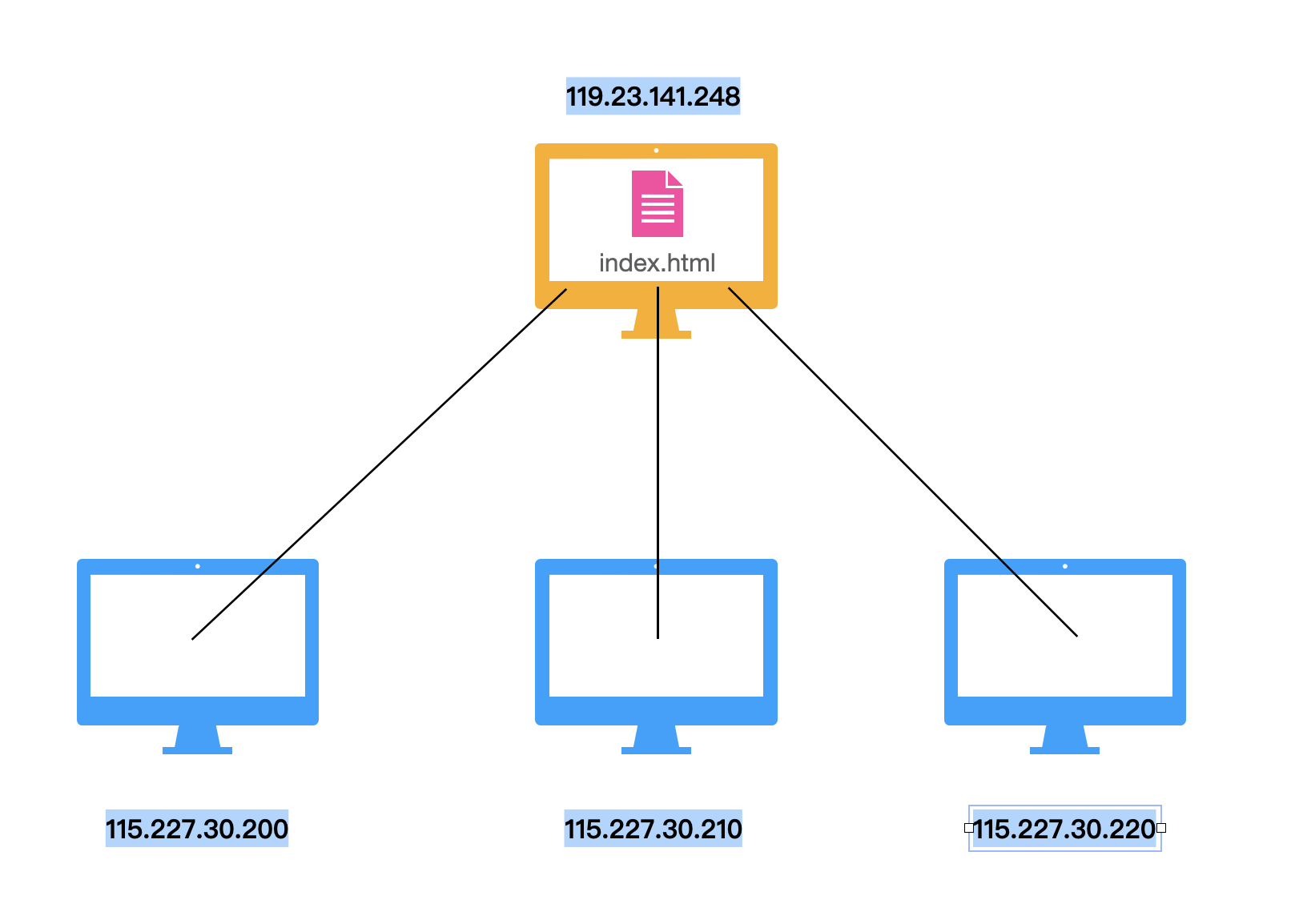
在上面这张图中,描绘了一个多个计算机访问一台计算机上内容的情况。在这个过程中,虽然下方的每台计算机都是想要获取同一个 index.html 文件,但是他们都需要访问这台地址为 119.23.141.248 的计算机并与这台计算机建立通道。这会重复的消耗这台计算机的网络资源,这显然是不高效的。而访问同一个文件会重复消耗计算机资源现象,也导致了现在网络世界中 DDOS 攻击泛滥。
最糟糕的是下面这种情况。
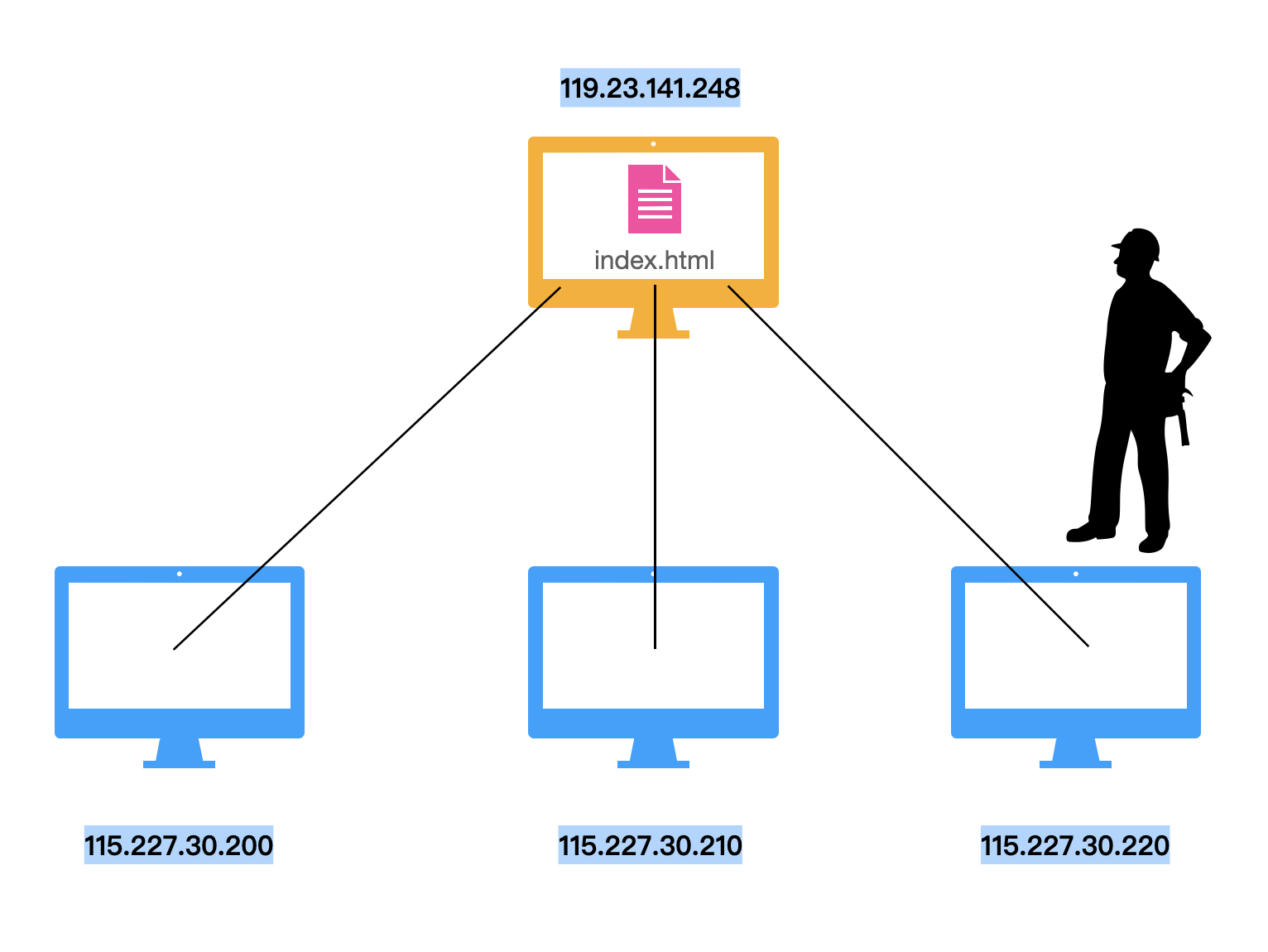
想象除了这些计算机外,出现了一个偷窥者,这个偷窥者用某种我们不知道的方法,可以看见并且修改这个通道内的内容。那么这些正在获取 index.html 文件的计算机们是没有办法能够验证这些内容是不是被修改过的。他们能做的只是想尽办法加密这个通道。而这就是为什么我们现在有了 HTPPS。
而命名数据网络则解决了这些问题。在 NDN 网络中,我们不再需要关心地址,管道等一堆破烂事。我们只需要关心我们最想要关心的一样东西:数据。而我们获取数据的方式则是通过这个数据的「名字」,这也是「命名数据网络」这个名字的来源。在大部分情况下,这个「名字」会是数据的哈希值。哈希值是数据唯一的名字,只要这个数据发生了任何的变化,它的哈希值都会发生改变。所以我们可以利用这个特性来验证我们获取到的数据有没有被篡改过,这样就消除了偷窥者修改数据的可能性。
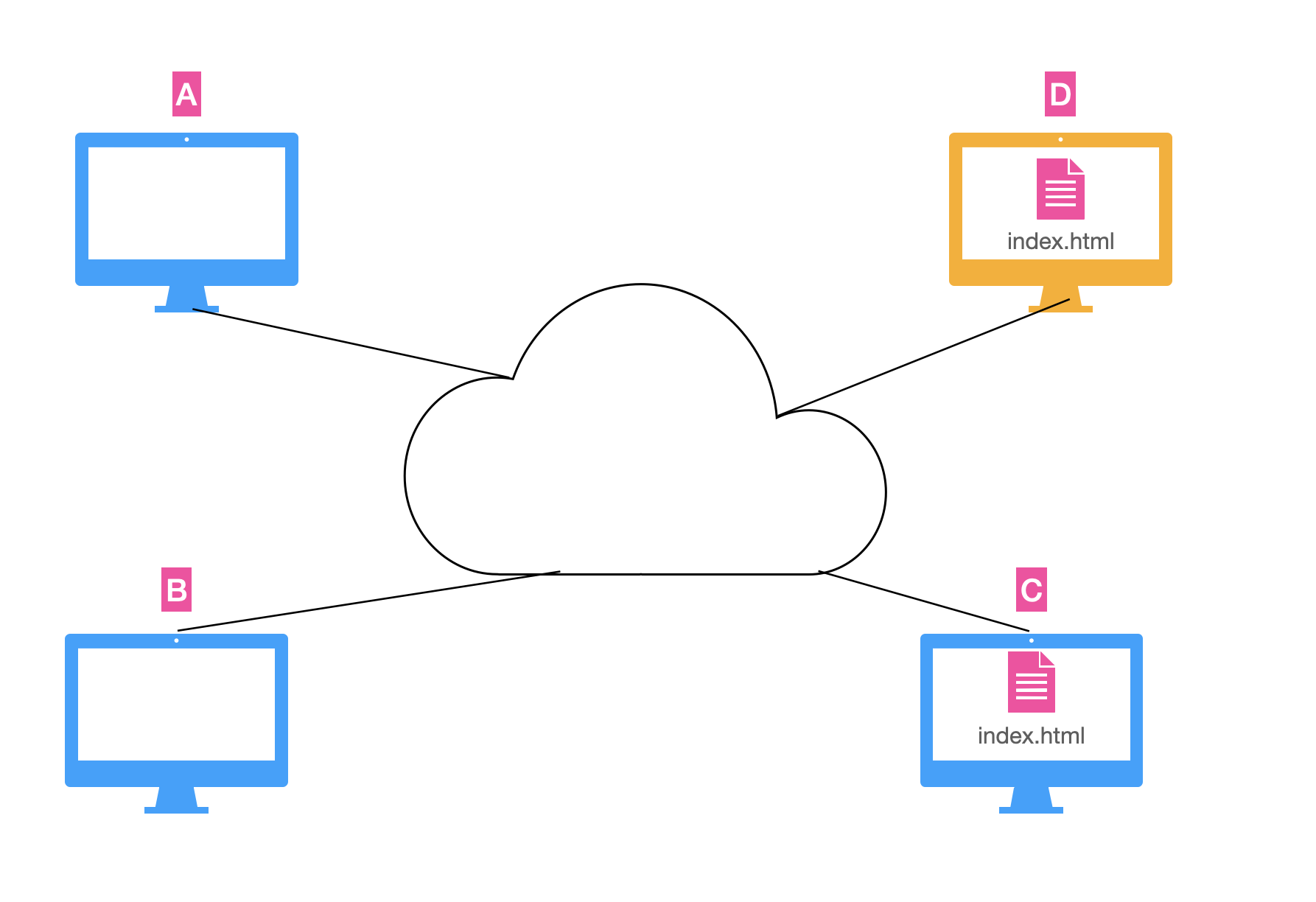
而当你不用再关心你要的数据存放在哪里的时,你就会发现,只要是数据是你要的数据,哪怕这个数据不是从最初的发布者那里来的也没关系。比如在上图中,计算机 A 如果想要文件 index.html , 而计算机 C 之前从最初的发布者 D 那里获取过同样的文件,计算机 A 其实可以直接从 C 那里拿文件,而并不一定要从 D 那里拿文件。当然其实在大部分时候 C 其实是路由器,如果对具体的原理感兴趣可以看张丽霞教授的一个演讲。
除此之外,命名数据网络还有很多其他的好处,但是因为篇幅所限,更多详细的细节比如:命名数据网络在物联网中的优势,具体数据包的种类,路由是如何传播的等,都可以去看我上面提到的张丽霞教授的演讲。
命名数据网络在提出之后,启发了一个全新的计算机网络的领域,这个领域被称作 Information-centric networking(信息中心网络),而这个领域的研究成果很可能在未来重塑我们的网络世界。